Product Support Specialist case study
Supercharger is most useful when a role is broad, technical, and easy to under-prepare for with passive reading. A Product Support Specialist role for a fast-moving AI product is exactly that: it can span API debugging, identity providers, customer communication, logs, command-line reproduction, escalation quality, and judgment about model behavior.
This case study shows how Supercharger frames that kind of role as a proof artifact: a structured skill map, realistic practice tickets, and validated work before claiming confidence. The practice is not only terminal work: the learner also has to compare evidence, decide scope, and write support-safe updates.
Role signal
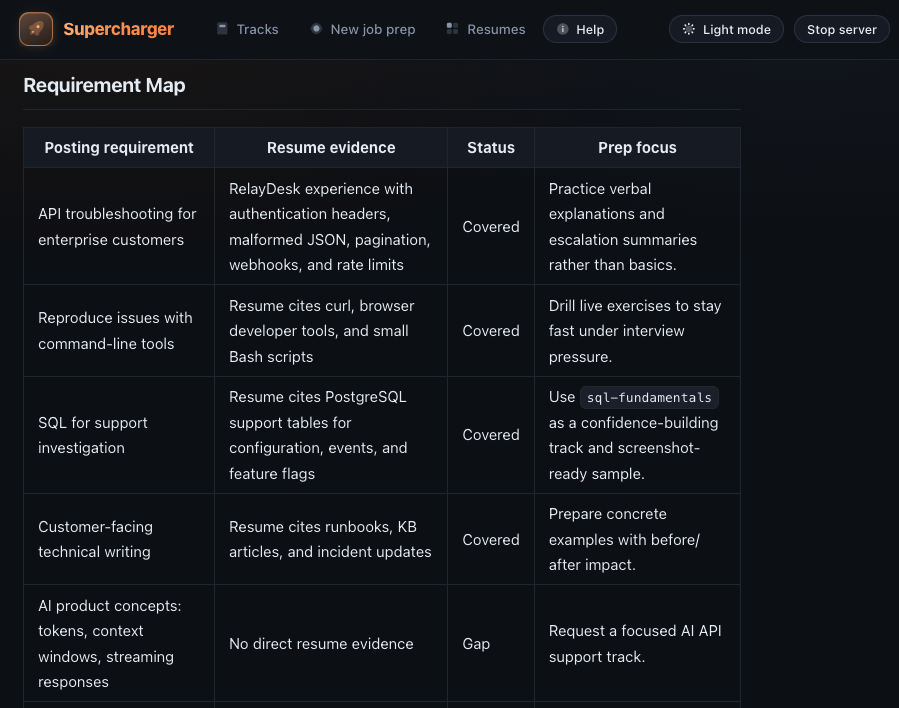
Section titled “Role signal”A support-heavy AI product role usually asks for more than friendly customer communication. Supercharger treats the posting as evidence and maps each requirement into concrete practice areas:
| Requirement signal | Supercharger study area |
|---|---|
| Debug API issues from customer reports | API request shape, auth headers, status codes, request IDs, retries, rate limits |
| Work with technical SaaS customers | Support case lifecycle, reproduction discipline, escalation writing |
| Understand identity providers | OAuth, OIDC, SAML, SSO terminology, common configuration mistakes |
| Use command-line tools | Bash, curl, environment variables, JSON inspection |
| Read logs and data | SQL for support queries, timestamps, NULLs, joins, exports |
| Communicate across personas | Executive summaries, engineer-facing repro steps, empathy without vagueness |
| Understand AI product limits | LLM capabilities, failure modes, safety constraints, expectation setting |
| Improve support foundations | Reusable runbooks, internal enablement docs, repeatable practice tracks |
When the posting implies a stack without naming it, the prep flags that as an assumption instead of silently pretending certainty. For example: “identity providers” may imply Okta, SAML, OIDC, or enterprise SSO; the prep should say what it is assuming and invite correction.
Example prep output
Section titled “Example prep output”The job-prep workflow creates three documents:
analysis.mdbreaks the posting into requirements, existing coverage, partial coverage, and gaps.plan.mdorders the study work by severity: what to skim, what to drill, and what needs a new track.interview-prep.mdturns the role into likely questions, model answers, follow-up chains, and talking points.
For a Product Support Specialist role, a strong plan might prioritize:
- API debugging practice with
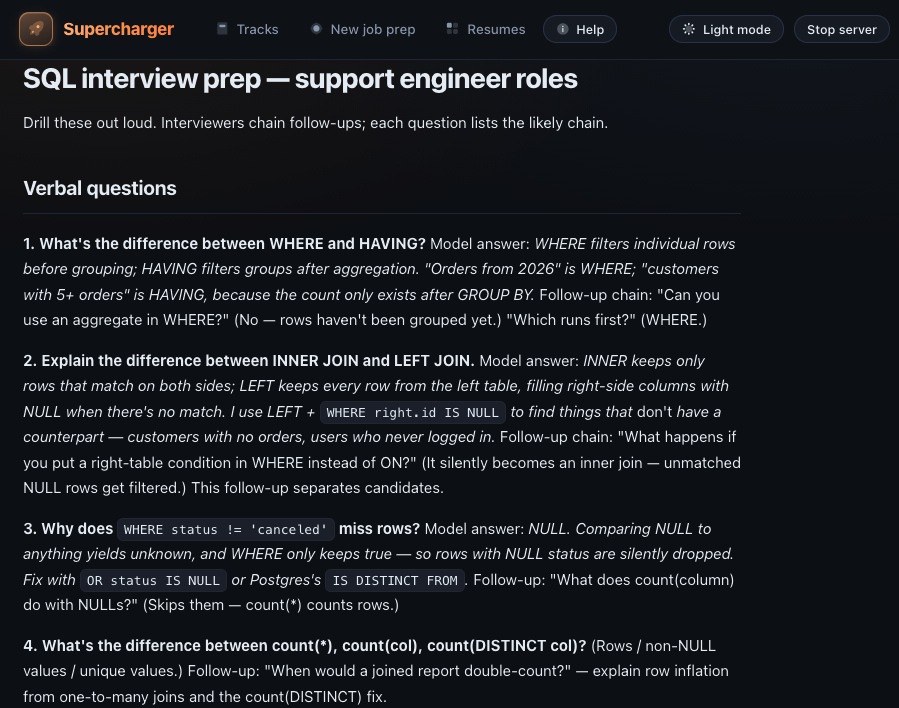
curl, headers, JSON bodies, request IDs, and rate-limit behavior. - SQL/log analysis for customer-impact investigations.
- OAuth/SSO vocabulary and common setup failures.
- Escalation writing that captures timestamp, account context, repro steps, expected behavior, actual behavior, and what has already been ruled out.
- LLM support judgment: explaining model limits clearly without overpromising or hiding uncertainty.
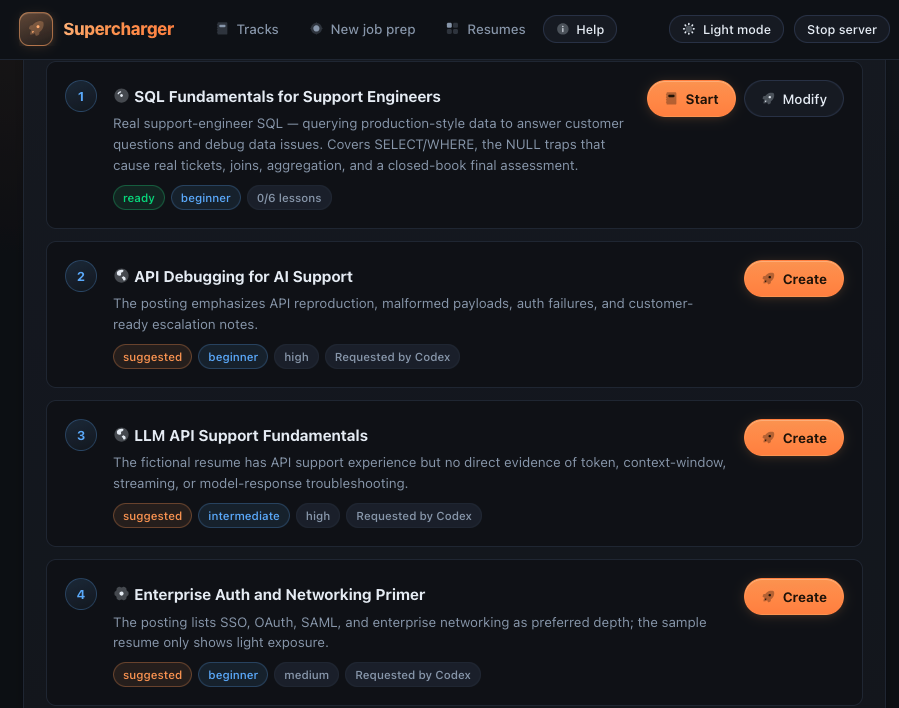
Flagship track idea
Section titled “Flagship track idea”A useful Anthropic-adjacent track would be API Debugging for AI Product Support:
| Lesson | Scenario |
|---|---|
| Reading API docs | Identify the required request shape and missing fields from a customer snippet. |
| Authentication mistakes | Reproduce 401/403 failures caused by malformed bearer tokens or wrong environment keys. |
| Rate limits and retries | Separate a real outage from client retry behavior and quota exhaustion. |
| Streaming responses | Debug partial responses, client timeouts, and malformed event parsing. |
| JSON failures | Find the difference between invalid JSON, valid JSON with wrong types, and schema mismatch. |
| Customer reproduction | Build a minimal curl repro with request ID, timestamp, and redacted payload. |
| Escalation final | Write the escalation an engineering team could act on without another round trip. |
The point is not to turn the learner into a backend engineer overnight. The point is practitioner fluency: knowing how to reproduce, isolate, communicate, and validate the common failure modes a support team sees every week.
Why this matters for support teams
Section titled “Why this matters for support teams”Support teams learn continuously: new APIs, new failure modes, new customer environments, new internal processes. Without a repeatable system, that learning becomes scattered docs, one-off explanations, and uneven confidence.
Supercharger makes enablement concrete. A senior teammate or AI coding assistant can turn a recurring issue into a reusable track, add a deliberately messy sandbox, and write checks that validate the work. The next person does not just read the runbook; they practice the ticket, explain the evidence, write the update, and prove they can handle it.
Verification over generation
Section titled “Verification over generation”Supercharger does not trust AI output blindly. The assistant generates
structured content against SPEC.md and AGENTS.md, but hands-on lessons are
validated by executable checks in disposable sandboxes. Structured practice
blocks cover the judgment around the command line: diagnosis, timeline
reasoning, escalation quality, and customer communication.
That distinction matters. The generated lesson can explain the scenario, but the learner still has to solve the ticket. The check script is what turns “I read about it” into “I can do it under realistic constraints.”
How to talk about it
Section titled “How to talk about it”I built Supercharger as a local-first technical learning tool for support engineers. It uses AI to generate structured tracks from a job posting or skill gap, then turns those tracks into realistic lessons with quizzes, structured practice prompts, Docker-based sandboxes, and checkpoint validation. I built it partly to sharpen my own support skill gaps, but also because I care about repeatable technical enablement: the kind of internal foundation that helps support teams grow with a fast-moving product.